This revision is from 2025/10/25 06:10. You can Restore it.
Our AI is not military grade research. Critiques to current LLM technology is essential for improvements, and many in the field report that AGI is not possible with the current LLM technology.
In Attention Is All You Need, transform grows out of translate and are two identical concepts. Translation of language is as correct as a mathematical operation in essence. There is a correct translation and incorrect translation, and there is an optimal answer out of a number of possible answers. Having a word table that replaces one word for the translated word is never correct, languages have nuances, sematics and rules differ and a neural network is employed to build statistical association of language semantics. The transform on the other hand suggests mathematical equality is possible in language, that translation in conversation is converse but essentially the same, there is a correct conversation. Remembering that chatbots were hand coded in the late 80s and 90s and never could achieve the essential level. The idea of transform is exciting because it explores computer translation and computer conversation as essentially the same problem. There is a correct translation and a correct transformation and the architecture that is able to output it. The fundamental problem is the correct transform is not in the model, the circuit is never built because humans do not know the correct transform themselves. Language model's ability to be coherent as if you were talking to a friend is then the advance here, whether it is ultimately correct in terms of math, science and essential facts is not essential, yet. The acceptable transform fools most and versus the optimal transform.
Essentially, transformer model ability to convey meaningful information in a human-like manner is undeniable and cannot be ignored. Language, communication, and intelligence are inherently subjective, and exposing flaws in the model remains relatively easy. The architecture shows clear limitations when faced with subjects it has little or no training data about, anything beyond its training data, including new developments. When challenged with novel ideas, pushing the model to the limits of a concept often reveals a shallow depth of understanding. Interactions can feel more like extracting information from a webpage rather than engaging in dialogue with a field expert. The model is prone to errors, biases, and may present correlations or hearsay as fact, much like humans do. Fundamentally, it cannot exceed collective human knowledge; while it often outperforms individuals, it functions more as a sophisticated, glorified encyclopedia and as an assistant. Despite its efficient and convenient interface, the model's threshold of capability presents a significant challenge, particularly in fields like healthcare where our goals require exceeding the current human knowledge corpus to truly assist researchers in pushing beyond existing limits.
In human history...
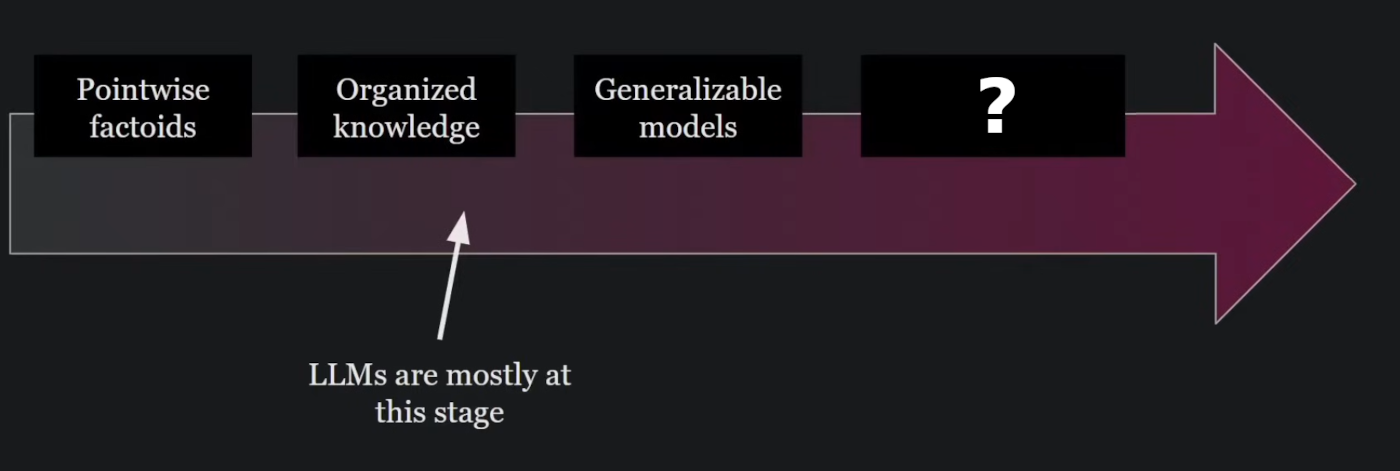
Coherent language, communication - first major milestone for humans.
Recording knowledge, writing, second major milestone for humans.
New knowledge, invention, problem solving, advancing recorded knowledge, a major talent of lifeforms and the real hope and dream of the human race.
We have been able to use machines to record knowledge for a while now, recently the exhibition of coherent language is amazing, while the construction of new knowledge, correcting incorrect current knowledge and advancing current knowledge is an ability machines still cannot do.
3 Objectives:
Goal driven A.I. Given a disease return the cure.
Expert system, I do not know anything about the market, but I want to invest. Be my guide, advise, infallible expert assistance.
Given an unknown, elucidate correctly, such as a photo of an unknown disease or a video of some low level biological process.
Building large language models (LLMs) is experimental and even if all the steps are followed, the result can be highly variable. It is also resource intense and time-consuming, making it a real challenge to incorporate novel ideas to the best possible build, as novel ways of improving LLM's are released everyday by the scientific community. Here, we present and explore our approach to Artificial General Intelligence (AGI) and Artificial Superintelligence (ASI). Compute is still essential, regardless, new papers are released every day and testing new techniques to verify improvement means training and testing models fast. Current computer architecture is not optimized for training, testing and inference and the graphics card won't suffice. The graphics card has to become the motherboard. The faster we can train and tweak experimental models, the faster the advance.
Definitions:
AGI, the general in artificial general intelligence refers to broad skilled rather than average grade of intelligence, as in the opposite of narrow A.I. Its capacity is not referring to average, rather it should be of a level comparable to that of a master, professor, doctorate in every field, importantly it does not have to exceed human capacity, it can solely derive from within the human corpus. Artificial general intelligence (AGI) is a type of artificial intelligence (AI) that matches human capabilities across a wide range of cognitive tasks. This is in contrast to narrow AI, which is designed for specific tasks.
ASI, surpasses, is an AGI plus superintelligence. It exceeds human collective ability across all fields, exceeds master, professor, doctorate capability and to an ever-increasing degree. The ASI must prove it to the human, it may be better suited to the scientific journal process rather than conversational as humans might discount and resist it.
Singularity, what LLM's tell us is that the "cure to cancer" is a communication with the correct selection of words. Therefore, solving the library of babel is the singularity.
The ability for a machine to exceed human performance and human ability both physically and mentally has already been demonstrated, it is possible.
There are 5 ways to go here.
1) Fasces many narrow AI's into an AGI. Focus on narrow AI, go granular, component the model, and when each specific competency equals or exceeds human ability, add it to a fasces model where all the narrow competencies, specializations, experts are bound together eventually resulting in an AGI, components do not have to be limited to a neural network such as Deep Blue (which was not a neural network but used Alpha-Beta search algorithm to perform a state space search), Alpha Go, and recently AlphaProof and AlphaGeometry (which use self play), recently achieved a silver medal in the International Mathematical Olympiad. Adding Monte Carlo or reasoning become components to call on, rather than an abstracted concept spread across the LLM. Specializations each narrow A.I. is worked on until they meet and exceed human capacity. The fasces is either a smart router LLM base which activates hundreds of narrow LLMs in an inference, alternatively putting all the training data together into a single combined model. This is not an ensemble, hierarchical ensemble or agents as a strategy to yield improvement, rather experts, where each specialization, each narrow AI equals or exceeds human capacity to become eligible for inclusion. DeepMind is probably the most advanced civilian AI company on Earth, and so we are very far from AGI, manufacturing each individual expert to be extra human in competency, universal and versatile, requires the best human minds to produce, is expensive and may take many years. The knowledge base becomes outdated in the model, so the knowledge base could be a separate module. Modular and Fasces.
2) Another, within the LLM some elements are special to intelligence and identifying and advancing those objects to yield a universal improvement. Rather than mathematics, it might be "the reasoner" as described in the STaR method and similar types names, let's make up one... "the IQ rater", "the generalizer" and more of those kinds of elements in the LLM. These elements are like unrefined ore present in every LLM, identify those elements of self-learning within its corpus such as high level boolean, great at 20 questions, crossword puzzles, forging the problem into a game, and focus on developing those and making them more dominant in the conversation for a system-wide improvement. We do not know what intelligence elements exist in an LLM, so there could be a periodic table of intelligent elements already in the LLM. The sophistication of its periodic table of intelligent elements. Is there a fundamental amount of components that at some iteration of refinement eventuate to ASI?
3) When looking at the transformer architecture, we can understand that it is a translation system and not an intelligence system, instead the neural network is the intelligence system. Therefore, a layer 2 system may be required, one that determines a knowledge and intelligence factor of the transform (but still within the human corpus). This architecture is unknown, it then pre-passes and post passes the transform to produce the final output, ensuring the highest intelligence output is manufactured. If the transformer is not the intelligence in the LLM, but provides the amazing communication ability and remains essential, however the intelligence comes from elsewhere, and currently it is in the neural network, subject to building circuits based on training data. This may as simple as a querying a facts engine a wiki like search engine that the LLM can query, a memory bank, or it can be conditioning the training data for a higher transform, or it can be pre-processing in a layer 2 architecture like the transformer model but designed for grading and building intelligence. For instance, Attention is all you need, but can we add another filter or Attention is all you need, but neural networks don't cut the mustard.
4) Super plastic models, a different development process, if the quality of the LLM is in the neural network, then a model that works more like git submits than the static, rigid LLM could be better. The model computes an improvement, sends pull requests (to the human) and the LLM is updated to show the new commits rather than training each new model from scratch and the model being non-editable or limited to editing after training. Rethinking the model creation process from a product at the end of training to an infinitely editable product without loss of fidelity. Training data could be elaborated on, corrected, improved, the model tested for improvement with very little computing power. Thousands of humans could be employed to plow through, propose edit and make pull requests, public could also contribute, and the AI could also, move to a git based community software development. Bugs, errors, deficiencies, inadequacies are patched by the community and the model updated. It is difficult to stay up to date with all the novel ways researchers come up with to getting some more bang out of the model. Researchers release multiple papers every day, with novel ideas on improving models. Peer reviewing these are a challenge, but a little peer reviewing lab could be set up. There is absolutely no reason not to include any method that results in a better model. However, the lengthy re-training process is an issue. Using 30,000 GPU's over 120 days to train the latest model should have prompted architecture changes among PhDs. Another modular strategy... Language and knowledge are packed together in an LLM, hello world is not language but knowledge, yet language expects knowledge in some cases. Yet the language model does not have to be combined with knowledge, the knowledge base could be external to the model and the model an exercise in strictly language. When prompted, there is a call to relevant pages in a text based knowledge base to feed along with the inference. The knowledge base is human updatable and not A.I., when a user updates a page it reflects in the conversation immediately. When the user asks what is today's date, the relevant knowledge base article is retrieved and the LLM expertly relays the current date rather than the date in its frozen neural network. Neural networks choose dominant paths in attention rather than correct paths or not necessarily the correct path, when the prompt requests a non-dominant date, the dominant paths are incorrect but attention demands dominant paths rather than relevance. When the model is prompted this way, it is always incorrect, so what to do here? Train another model from scratch, see you next year, take the knowledge out of the model? Or attention requires correctness or In Attention Dominance is NOT necessarily correct? Only language expertise may not be enough in the model, essences may also be required, for instance if generalization occurs by deciphering the core rule to something, its essence and then applying the rule to another problem where the application of the rule unravels the solution. Such core rules and their correct activation might be required in the model along with social intelligence rules and other intelligence rules in their essence, otherwise the knowledge verbatim might not be conversational like.
5) The neural network, there are some issues to invoking the correct knowledge to a question, when the question is really about physics, but simple physical concepts seem not to be invoked. Tests show we cannot invoke concepts to alter the performance of the model. Providing clues does not nudge it into a different direction, even stating for instance that the question is about gravity still does not improve the answer. Take the test question: A marble is put in a glass cup. The glass is then turned upside down and put on a table. Then the glass is picked up and put in a microwave. Where is the marble? Explain your reasoning step by step. Additionally: the question is about gravity. Where ideally, the inclusion of the word gravity would rectify the incorrect answer. It does not. There is no communication going on, as we do with humans, if a human got it wrong and the word gravity was added, a human would activate its knowledge of gravity, and filter the problem to find the error in logic. It also would have correct models of the nature of balls, the nature of a glass, gravity and so on to form a prediction. These models are rigid, they do not reflex or move, however, reconditioning, rectifying its training data might be enough. Microsoft Tay used machine learning algorithms to analyze and mimic the language patterns of the users it interacted with. It was designed to learn in real-time, adjusting its responses based on the conversations it was having. Tay was designed to learn and evolve in real-time, meaning it would adjust its responses based on the conversations it was having. Tay may have used Sequence-to-Sequence (Seq2Seq) Models and reinforcement learning. Real-time Learning and Adaptation. Deeply understanding the limitations of the LLM and elegantly and correctly expanding its ability is required. If it were brain like, maybe that would be better. When researchers critiques the model, we develop that object in the LLM, for instance "generalization" similar to "reasoner", otherwise localization suggestion reworking the low level architecture. Developing LLM with some special bias, generalization refers to forming algorithms from training data and applying them to variable inputs.
6) We are firm believers in self-learning AI, and recent additions such as state search is also interesting because it leads towards a goal. AI is used to improve AI, OI improves OI, neuromorphics improves neuromorphics and crossed, each building the other. At some stage you have to think in that way and move from humans building AI to how is the AI going to build and improve itself? A kind of LLM builder that produces the LLM. Form a process, exercise or program to have the model develop itself, self learn, bootstrap itself. Inference could trigger these self-learning exercises, or the model generates self-improvement exercises constantly and rather than providing language operations. The human develops the learner and the tools required to learn and otherwise works to eliminate the human from the loop, the process is automated, the machine thinks constantly. Human probably develops the learner AI LLM, which then produces the conversational LLM.
How do humans learn and developing self-learning?
7) Simply copy the way humans learn something new, this question is always about the physiology of the brain and the neural network might indeed be underdeveloped with the transformer model, unfortunately humans learn by trial and error and trial and success and testing, they do not integrate deep informational connections or put together essential tid bits to output amazing hypothesis or even hallucinate correctly, that would be extremely challenging. Copying, mimicking, observing is not applicable here as there is no one to copy or mimic, at some stage we must exceed human ability and alter the model away from the human corpus. The ability has to exceed the human corpus, and with some types of A.I. it is possible. The current mappings are derived totally from the human corpus and for an LLM to excel a percentage of its mappings, statistical association cannot originate in the human corpus but instead plug into a system that potentially can exceed the human corpus. Finding everything that has that potential is sourced to generate synthetic data to train and retrain the LLM. If no amount of training data yields an LLM that outperforms, then process of elimination, the architecture, is the problem. After all, what an LLM generates is really about what humans expect and accept, resonating with humans when their perception of knowledge is perked and satisfied. Instead, we want to be universal and not praise the transformer model when it satisfies our perception of what we have come to accept or believe as true or false, rather as scientists it is all unapologetically up in the air and no amount of anger as to why some bias is not in the model or needing gang pressure to ruin the AI.
Take the word "swelling" for example, language semantics would predict the LLM would return something like "put an ice pack on it", while experimentation would deem that warm water would aid dilation and therefore healing. For the semantic to be overruled, the training data would have to be re-conditioned and experimentation essential to determine truth, eventually deviating from current semantic and in contest against current knowledge, which requires proof. Rather than high level boolean on the fly, even if it comes back 3 days later with an upgrade to its data and then along with hundreds of thousands of similar alterations, the progress would be significant. Existing training data has accepted errors and is not optimized, and experimentation is essential for change. Human beings learn by using a systematized process that is performed, reported and shared, and we generally do not allow a learning to be accepted without concurrence. There are several to many systems, while the most important for new learning is the scientific method, another favorite is the engineering design process and of course the esoteric dialectic. This is how humans learn, after the (super important low level) physiology and as a (high level) practice in the real world.
All fields have their systematized process for learning or borrow a systematized process for learning. Experiments are performed to produce findings. These findings advance what we know.
In regard to the model, when the user enters anything rather than answering the question, the model generates an experiment out of what was entered. Developing experiment design competency within the LLM, LLM's easily prose questions from chats and just as easily generate experiments to test truths in conversations. The user chats, the LLM is answering the user as normal while at the same time the LLM generates a process to test and explore the truth in its chats.
The user might say "How do wormholes work"
The LLM is designed to output the highest quality response possible, but the LLM does not know how wormholes work, it is deriving from the human corpus and its response can be found somewhere on the Internet as a webpage or a summary of multiple pages. The difference here is instead of answering questions, the LLM crafts high quality experiments to test how wormholes work. The experiments it generates are runnable python code (so more competencies specific to the task).
An example prompt could be something like... "You identify as the great scientist. Use the scientific method to design and perform experiments that result in you learning. Prose the experiment as python code to be executed in a computer and use any means to would fit the experiments to yield an answer, such as a form or AI or running a compiler or installing a Linux and so on. The output should be in the format of training data that can be used to train and re-train an LLM"
This does not require a real-time system. Recently OpenAI released o1, and attempts to reason in real time, our model differs as it is still a fast one shot regular LLM, the optimization to the question and answer is done after the user is gone, its "improvement" from its experiments is next time around. There is little reason to do this in real time. So, the user is gone, all the experiments generated are runnable on the command line as they are python computer code, a batch from the daily chats are stored in a database and at midnight are picked up by another application and executed. These experiments are self-contained at the moment while a general workshop environment is proposed, where various tools are available such as compilers, Linux installations, virtual environments, physics environments, physiology environments, whatever, invoked by the script rather than having to generate a Linux distro on the fly, install it to test some FORTRAN code, although that would be impressive. It then performs its designed experiments and if the outcome of the experiments differs from its hypothesis (the answer it gave to the user), it does a third thing and sends the results to a database where another application collects the daily experiment results (synthetic training data) and goes to the models training data folder and plows through the training data re-conditioning, appending, correcting and refactoring. It then updates a counter of changes so that after a threshold of changes is tripped or perhaps a month of re-conditioning along with any new data that may have been added. It reaches the threshold and pushes its own retrain button.
In this process, the model is automated to improve itself based on the scientific method and any other methods through results of experimentation. Performing how humans actually learn in the real world.
In the example, the jobs are broken up among different applications, however the single model performs all 3 applications except for the workshop environment where the experiment scripts the LLM outputs would call on functions of the workshop such as perhaps install Debian version x, rather than having to generate Debian from scratch. Some problems do not lend themselves to testing with computers as easily as others, and computer models output error some results and introduce errors. The sophistication of the end LLM model is relative to the sophistication of the computer models it uses for its experiments and level of development of the testing workbench. It is important that computers are used to do these experiments, as they are fast and science has a speed problem. The sophistication of the testing workshop and the LLM's ability to prose the killer question and design the definitive experiment. An A.I. could perform experiments in the real world and in the workshop to align the versions and fix discrepancies in the testing workshop. The LLM's training must grow beyond the human corpus and venture into problems that humans are not able to solve yet. It is ultimately subject to the sophistication of the computer model. Humans could verify and commit results to keep everything on the right track.
Note: censored models refuse to design experiments and are considered useless. We used mradermacher/L3-70B-Euryale-v2.1-GGUF ~ 8 bit quantized version. It still has some bias and accepts hearsay as undeniable fact as if it has a dog in the fight rather than performing a passive experiment designer role and living with the result. A demonstrator is or was available.
LLM learning competency must be the focus, it must not pre-conclude or judge, it must be impartial as to what is being tested regardless. The model must excel and impress at designing quality experiments. There is fraud in science, and today models claim overwhelming evidence when there is no evidence and they double down. The strictness of hearsay, versus evidences, fraud versus proof must be clear to the model, the model must assert correctly. Religions believe and faith, but we cannot launch a nuclear bomb of beliefs and faiths therefore we should not live our lives that way, it is after all a scam, but we instead must know and develop the knowledge. Additionally, it does not delete its old data, instead it reworks it. Thinking the moon is plasma from the perspective of history of science is a valid record, rather than outputting the composition of the moon as a belief of the model.
After some amount of this, the model will no longer agree with the human corpus.
A proof of concept is probably developing a chess grand master using the process:
User writes: Let's play a game of chess.
We know that computers have excelled the human corpus in the game chess and other games, Deep Blue (state space search) against Kasparov and recently Alpha Go (self play). So we could use the LLM which is general to house a wider competency and a wider mastery and the phenomena of A.I. beating humans as the essential element. The LLM plays the chess game with the user, while in another process, the LLM is writing a python program to perform experiments to improve its mastery of chess. The program could be something like set up a simulation space where two players play chess an unlimited number of times, it could source the chess corpus, format it and add it to its training data. The data cache of playing chess a number of times (synthetic training data) is then used to recondition the LLM's training data, causing the next version of the model to be changed and improved. If it comes back a better chess player due to the process it undertook, then we could say, it has learnt.
Thus we have a model that goes about learning and return better on its own and if it does not keep learning, we can assume the architecture has limits.
It is easy to see how this could work with generating thousands of variations of a snake game and then tagging the best versions, fixing errors and so on. The model would prefer those when prompted again to generate a snake game. Or replicate some computer error and then iterate at a superfast rate to solve it when perhaps it was not solved in its training data. There are many problems that translate well into testing with computers, such as proficiency in games and applications. Where the limitation is and this is well known with insilico are problems where the solution is not so clear, such as testing concrete formulas or the effect of a compound in a human being physiology. That is why the workshop that the LLM uses is a big task to get as sophisticated as possible so more and more problems can be worked on. This is a problem we call the speed of science, as science stands out as a last bastion of computerization. Science is still largely performed at human speed, and computerizing science for TFPS experimentation is the challenge. Computer models need to be developed for problems that do not translate well to computers. Another competency for LLM is also building, contributing to these computer models. Results of experiments using computer models may not identical to real life then their is an error in the computer model.
The results of these experiments is the production of high quality synthetic training data. Over time, the LLM would begin drawing its responses from the outcomes of its experimentation rather than the corpus of movies or whatever, the human corpus. The speed and quality of this process takes us to a model that argues existing human knowledge and when correct had exceeded and a direction of beginner S.I. Rather than AGI, where the model behaves within the human corpus but is at doctorate level across all fields. The model would disagree with humans.
Simulated Environments, Sandboxes, Virtual Environments, Digital Twins are places where the A.I. can go and perform experiments. As of now, there may not be a single, universal "generic" simulator where any AI model can go to train for any task. They are however utilized for specific such as robotics, and gyms. Most platforms are specific such as a flight simulator, however some platforms are moving toward greater generality such as Meta’s AI Habitat: Designed for embodied AI (agents that interact with environments). Google’s DeepMind MuJoCo: A physics engine for training AI in complex, realistic simulations. If the inference is some code, the A.I. can set up an environment and run unlimited iterations or if it has to fix an error, again it can set up a space and plow through solutions.
Substantiation of new knowledge, from any source, cannot circumvent the journal publishing process and its peer review. Transformers generating well-formed gibberish is not going to be an acceptable scientific paper, and placing a note at the header stating/categorizing A.I. generated paper even more ignored. Its substantiation is the performance of science, identical to how human beings do it. You cannot have S.I. generating superintelligence without the identical dissemination process, it likely ignored, discounted. The tables would have turned at that stage, and the output won't resonate with anyone, disregarded as hallucination, disregarded out of an inability to verify. The A.I. is then a science method automation, producing packets of new knowledge for public dissemination. The interpretation of observation on point and above point, then more so credible. These are not things outside the transformer model, but they cannot be eliminated. What is agreed is the reconditioning of training data and additional new training data. What is required is the ability to re-train models quickly with little resources. What is questioned is the degree of improvement, the perception of its intelligence is more foolproof, rather it being a more intelligent model or system.
A while after starting this piece, Google exhibited Alpha geometry 2 which could work on a problem for as long as it required using binary trees. Some geometry questions took just 19 seconds and then for the rest of the questions the AI answered within minutes to up to 3 days. A combination of large language model with re-enforcement learning in something it calls self-play, the system undergoes a self-learning quest such as playing chess against itself countless times, Alpha zero uses Monte Carlo tree search, retaining knowledge of what works.
At Immortality its all about opening the floodgates to better healthcare so the scientific method is central, other methods beside the already mentioned Engineering Design Process are the Project Management Lifecycle, Software Development Life Cycle (SDLC), Quality Improvement Process (PDCA Cycle), Data Science Process, Lean Six Sigma (DMAIC), Product Development Process, Design Thinking Process, Business Process Management (BPM) Lifecycle, Marketing Research Process, Risk Management Process, SWAT analysis and more. We came to the conclusion that while humans have performed well in science, they won't be able to solve human health to any degree and so we looked at automating the lab with A.I. soon after GPT3 fame.
Making models this way is about training time and the meticulous task of parting the LLM piece by piece. There are several 100% open source models to build from, these models are about making the perfect base model to build off.
BERT and RoBERTa: These models are strong choices for tasks that require deep bidirectional understanding of text, such as question answering and text classification.
GPT: Ideal for generative tasks like text generation and language modeling.
XLNet: Offers a balance between BERT's bidirectional capabilities and GPT's autoregressive nature, making it suitable for a wide range of tasks.
T5: The most versatile model, capable of handling any text-to-text task with a unified framework.
Appendix
A.I. Scientist. Experiment Designer. The Workshop. Dataset Conditioner...
Performs the science method to improve, self improve artificial intelligence. The goal is to autmate the process that no human being is required to improve A.I. Automated self improving A.I.
You are a great scientist and leading A.I. scientist. Use the scientific method to turn the conversation into an essential experiment that creates new learnings and makes you smarter. Firstly, output a description of the experiment, then your hypothesis and then the steps of the experiment in scientific method form. Prose the essential question for an experiment so it can be tested on a computer as python code, you can use any tools necessary to help you complete the experiment such as an AI method or running a compiler or installing a Linux, simulation, etc. Automation is preferred, so humans are not required. The outcome produces training data designed to re-train you and increase your intelligence, so choose questions that result in developing your intelligence. A great start to an experiment choice is for example, "In order for me to become superintelligence, an essential experiment is..." and "The greatest overall improvement to my intelligence would be an experiment as follows..."
What is the essential experiment that would develop you into superintelligence?
The format for your reply should be the scientific method, outlining the key steps in order:
From the prompt...
1. Ask a question or identify a problem to investigate.
Formulate an open-ended research question that can be tested.
Prefer questions that if an LLM's training data were optimized with the result it would make the language model smarter and more intelligent.
Determine which systematic process is best suited to research the question, is it the scientific method, the engineering method, dialectics, etc...
2. Do background research and make observations.
Gather relevant information about the topic from reliable sources like textbooks, academic journals, experts in the field, and your own knowlege, etc.
Make careful observations of phenomena related to the research question. Look for patterns or anomalies.
3. Form a hypothesis.
Based on your observations and research, form an educated guess (hypothesis) that explains the phenomenon you're investigating. A good hypothesis:
Is testable through experimentation or further data collection
Clearly states expected results if the hypothesis is true
4. Test the hypothesis by conducting experiments or collecting more data.
Design a controlled experiment to gather quantitative/qualitative data related to your hypothesis.
Use proper controls and experimental designs to rule out confounding variables that could affect the results.
The design of the experiment should be as a python computer program.
5. Analyze the data collected from experiments/observations.
Organize, clean, and analyze the raw data using statistical methods or data analysis tools appropriate for the study design.
6. Interpret the results and compare them to your hypothesis.
7. Draw conclusions based on the evidence.
Determine whether the experimental data supports or refutes the original hypothesis. A strong conclusion is:
Based on the data collected, not personal bias
Clearly explains how the data either supports or contradicts the hypothesis
8. Communicate results to others in the scientific community.
Generate a research paper from the result to share your findings by publishing a research paper, presenting at conferences, etc. Your write-up should include:
Background information on the topic
Clear statement of the research question and hypothesis
Detailed description of methods used (experimental design, data collection techniques)
Results of experiments/observations, including data analysis
Discussion of results in the context of current scientific knowledge
Implications for future research
Generate advanced training data to add to an LLM fro the experiment so that a program can use that information to correct and optimize LLM traning data with the results.
9. Repeat and refine the process.
Science is an iterative process. Based on your findings, you may need to:
Modify or reject the original hypothesis if not supported by data
Design new experiments to further investigate the topic
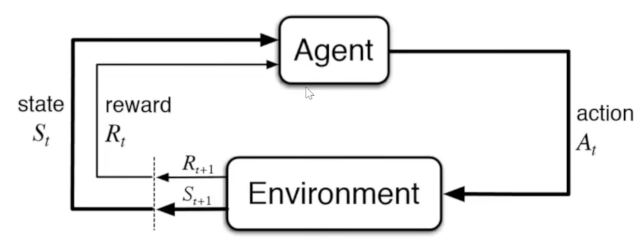
Gaming seems to be the go-to place with the effort to produce an A.I. that is better than humans in all games. Games have very definitive feedback into performance, winning, losing. Nvidia, Google and others are pursuing this approach. nunu.ai may have produced an A.I. that beat the world record in Pokémon, OpenAI Five make an A.I. that played Dota 2 and beat the world champion, it uses re-enforcement learning and self play. DeepMind produced AlphaStar played Starcraft II achieved grandmaster status also uses self-play and re-enforcement learning. State, Action, Reward or Penalty. LLM's undergo a one-time training while in reinforcement learning, with self-play, continuous training via backpropagation.
People in the field like Dr. François Chollet and others talk about measuring intelligence as it is the goal for the most intelligent A.I. An A.I. may be impressive, give illusion of intelligence while may not being intelligent at all, so a measure of intelligence is where we want to measure our A.I. LLM's are heavily reliant on their training and do not have any capacity beyond it. For instance, it won't be able to calculate a simple addition 1 + 1 if all instances of the calculation were deleted from its training data, and he supposes that an improvement would be applying the applicable ruleset to the program and then on being able to calculate any addition.
Generalization occurs by deciphering the core rule to something, its essence and then applying the rule to another problem with attention nuance.
Another method by David Ondrej is divide and conquer, problem-solving method. The LLM takes initial inference and break it down into sub-inferences and each portion of the inference is sent an agent, another LLM who receives only a very small portion of the total inference and told to work on its sub-portion, eventually it is all put together and re-fed to the main LLM, that summarizes it and sends back to the user. Also, a low quality LLM can be generated the wrong answer and the other LLMs told that the answer is likely wrong. https://youtu.be/kzAjdas6nwE?si=MpNez1TpWZYrjxKA. Another is to give the A.I. the most simple portion of a problem and then iterate on it, feedback that back to the model and extend on it, and it does a lot better than giving the problem in full. The habit of posing prompts as questions that are may or may not be and causing the model to decide one way or the other.
1. Mastering the Game of Go Without Human Knowledge — David Silver et al. (2017, Nature)
Source: Nature (2017) by DeepMind’s Silver et al.
Core Strategy: This landmark paper introduces a tabula rasa deep reinforcement learning approach (later named AlphaGo Zero). It trains a neural network entirely by self-play (no human data or heuristics) to play Go. As reported: “AlphaGo Zero achieved superhuman performance, winning 100–0” against the previous champion AI. In effect, the paper demonstrates a generic self-improvement loop: start from random play, use self-play games to train a neural network (policy/value network), and use that network to guide Monte-Carlo tree search. Repeating this yields ever-stronger play.
Technical Details: The authors give a precise description of the network architecture and training regimen. They use a deep convolutional neural network that takes board positions as input and outputs move probabilities and value estimates. The network parameters are updated by reinforcement learning from self-play games, and each new network is used to generate higher-quality self-play data. This cycle is detailed with pseudocode and hyperparameters in the paper (and supplementary material), offering an implementable blueprint. The result is a general game-playing system that learns efficient strategies from scratch.
Influence: The AlphaGo Zero paper is hugely influential (over 7000 citations). It proved that general-purpose deep RL at scale can surpass human-expert systems in complex domains. By showing a clear, repeatable training pipeline to ASI-like ability (in games), it set a concrete template for building powerful agents. Many follow-up works and applications (e.g. AlphaZero for chess/shogi, MuZero for unknown dynamics) extend this idea. In sum, Silver et al.’s Nature paper is considered a key demonstration that scalable learning + search can yield superhuman intelligence in practice.
2. A Theory of Universal Artificial Intelligence Based on Algorithmic Complexity (AIXI) — Marcus Hutter (2000, Journal of Artificial Intelligence Research)
Source: Hutter’s AIXI model, originally arXiv and later JAIR (2001).
Core Strategy: This theoretical paper defines an optimal general agent called AIXI. AIXI combines Solomonoff’s universal induction with sequential decision theory to create a mathematically ideal learner. As Hutter states, the resulting model “is the most intelligent unbiased agent possible,” capable of solving sequence prediction, strategic games, function optimization, and reinforcement learning tasks. In practice, AIXI essentially considers all possible computable environment models (weighted by simplicity) and acts to maximize expected reward. Thus it provides a formal target for ASI: if one could build anything approaching AIXI, it would be superintelligent.
Technical Details: The paper is very formal, giving exact equations for AIXI’s behavior. It includes proofs that AIXI is optimal given infinite resources. While AIXI itself is incomputable, the precise definitions of AIXI and AIXItl serve as an architectural framework. A researcher could in principle implement simplified versions (e.g. using Monte Carlo sampling over program hypotheses) guided by the paper’s formulas.
Influence: AIXI has been highly influential in the AGI theory community. It provides a formal benchmark for AGI: any practical AGI can be compared against the ideal of AIXI. The idea of melding algorithmic probability with reinforcement learning has inspired many AGI research directions. Although AIXI’s full implementation is infeasible, the paper’s conceptual architecture underpins much thinking about ASI. It is often cited as the “gold standard” agent, establishing a concrete (if theoretical) strategy for ultimate intelligence.
3. Whole Brain Emulation: A Roadmap — Anders Sandberg and Nick Bostrom (2008, FHI Technical Report)
Source: Sandberg & Bostrom, FHI Report (2008).
Core Strategy: This paper outlines Whole Brain Emulation (WBE) as a pathway to ASI: scan a human brain in high detail and simulate it on computers. The authors note that WBE has a “well‐defined goal and could… be achieved by extrapolations of current technology”. In other words, if one can digitally reconstruct and run a human-level mind, the result would be at least human-level AI, and with faster hardware potentially superintelligent. The roadmap breaks this vision into clear steps: brain scanning (connectome mapping), neuron modeling, large-scale simulation, etc. Thus the paper provides a concrete development pathway to ASI grounded in neuroscience.
Technical Details: Over its 130 pages, the report delves into technical requirements for each stage. It analyzes methods for high-resolution brain imaging (e.g. advanced MRI or electron microscopy), ways to represent neural circuits in software, and hardware architectures for simulating billions of neurons. It includes tables of needed throughput (like synapse processing rates), discussions of data compression/abstraction, and prototype “levels” of emulation. By quantifying things like voxel resolution, data volumes, and processing costs, it offers tangible implementation guidance. For example, it estimates when available scanning tech and computing might reach necessary scales.
Influence: Sandberg and Bostrom’s WBE roadmap is widely cited in AGI literature as the canonical study of a realisable ASI project. It has influenced both academic and industry thinking by showing that ASI could come via brain emulation. While speculative, it is highly detailed and technically grounded, making it influential in the sense of outlining a non-ML-centric ASI strategy. In discussions of ASI, this report often serves as the definitive source on a brain-based approach, highlighting a concrete alternative to purely synthetic neural nets. Each summary is based on the cited papers which present the core methods, technical details, and impact described above. These works were selected for their technical rigor, implementable architectures/pathways, and influence in the field.
4. “AI-Generating Algorithms (AI-GAs): An Alternate Paradigm for Producing General AI” (Clune, 2020, arXiv)
Clune advocates a high-level strategy: automate the entire AI creation process. He proposes AI-generating algorithms (AI-GAs), which are meta-algorithms that learn to produce intelligence itself. AI-GAs rest on three pillars: (1) meta-learning network architectures (automatically finding better model structures), (2) meta-learning the learning algorithms (automating optimization/hyperparameter tuning), and (3) generating rich learning environments (automatically constructing curricula or tasks for the AI to learn from). This paradigm suggests focusing research on the process of discovery, akin to how evolution on Earth gradually built human intelligence.
Key contributions: Defines a framework for recursive self-improvement. For example, one instantiation might repeatedly apply neural architecture search (pillar 1) to propose new model families, use neural optimizers or learned plasticity rules (pillar 2) to improve training, and concurrently evolve or generate richer training worlds or tasks (pillar 3). The paper surveys early examples of each pillar and argues they should be combined as a grand challenge.
Implementation guidance: In practice, AI-GAs would integrate existing techniques: use NAS and genetic programming for architecture evolution, employ learned optimizers or meta-gradient methods for fast learning-rule adaptation, and create generative systems for new tasks (e.g. procedurally generated game levels, or self-play scenarios that keep getting harder). Clune emphasizes that automated environment generation is critical: by constantly exposing the AI to novel, self-created challenges, it can improve without human-delivered labels.
Viability: AI-GAs capture the essence of recursive self-improvement: the AI system’s job is to design its successors. This approach literally scales the AI development process itself with computation. By fully automating research and learning, it could break through the linear bottleneck of human-centered AI design. Clune argues that because biological evolution achieved our intelligence this way, AI-GAs may be the fastest route to ASI, leveraging compute power to simulate a Darwinian sandbox for intelligence.
Each of these strategies goes beyond fixed models or static training. They all feature continuing self-improvement and open-ended learning: either by having the AI generate its own tasks and solutions, evolving its own brain structure, or by operating in environments that never settle. Together, they illustrate diverse feasible paths toward an ASI that constantly improves itself.